Huginn
Published on Monday, December 26th, 2016
Yahoo! terminated Yahoo! Pipes on June 4, 2015. It breaks my heart to see another good service dying. However, I recently found another project which has an ability just like Yahoo! Pipes: Huginn
Huginn seems to be more robust than Yahoo! Pipes, actually. The downside is that it is much more difficult to set things up. Also, it’s just an app. I need to either set up a local server to run it or host it somewhere. Since I’m too lazy to maintain the local server, I hosted it with Heroku. With the free plan, there are a lot of restrictions, but this should be enough for the basic tasks I want to do.
Here comes an example:
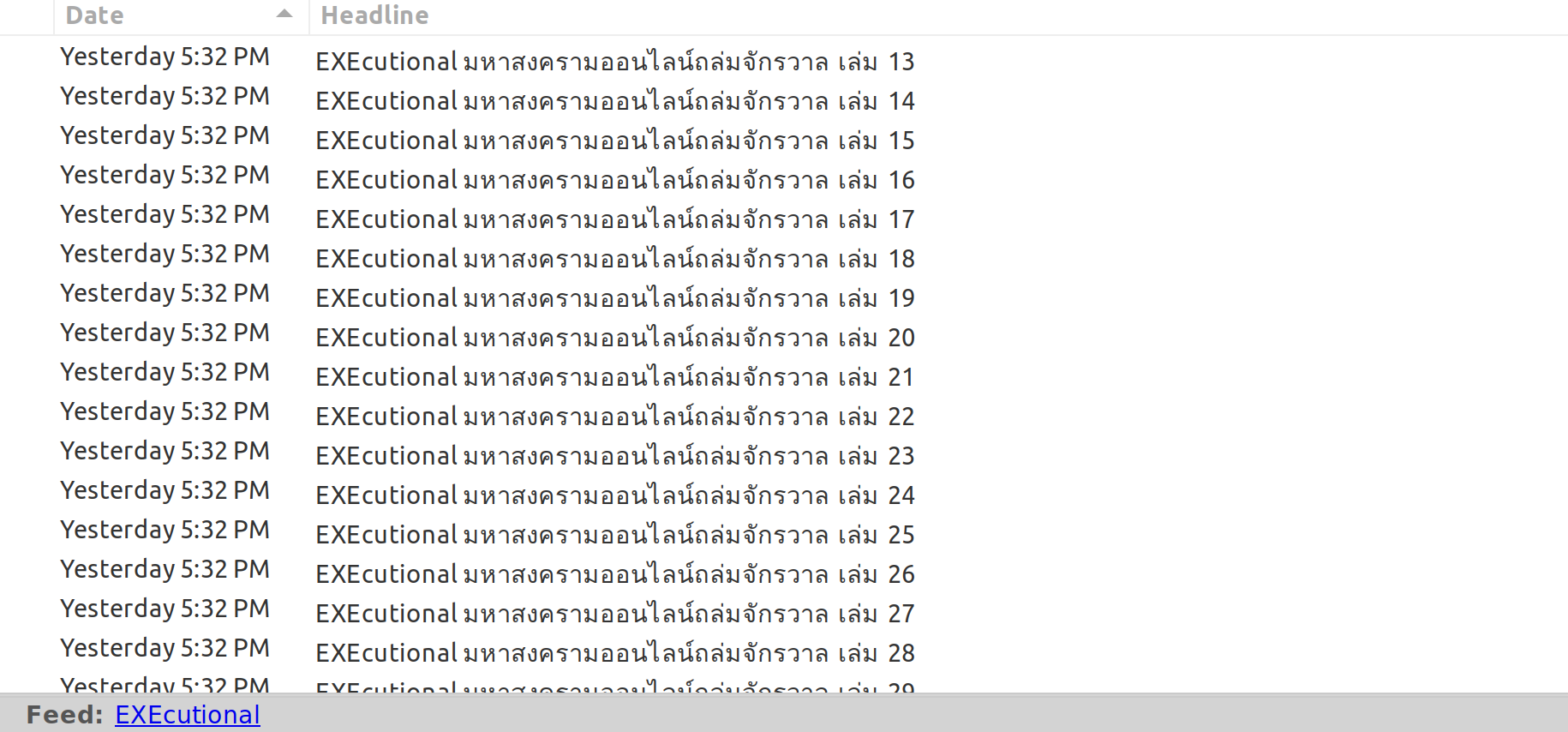
I am following a Thai manga named EXEcutional. For other manga, I would need to wait until I get back to Thailand and read them. Luckily, EXEcutional has an e-book version, so I could just buy it online. I however want to be notified whenever a new issue is released.
First, I curl the webpage to see if there is any data I could scrape. To my disappointment, there is no data at all. This means the data is likely loaded later by JavaScript, so I try to find the relevant code.
1 2 3 4 5 6 7 8 | ... <script > var series_id = '563'; //var series_name = ''; var app_id = 'ASK'; </script> <script src="https://www.mebmarket.com/web/Assets/Scripts/Templates/series_details.js?221"></script> ... |
Cool! Next I curl this JavaScript file, then I find:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | $.ajax({ type: "POST", url: "Ajax.php?action=CallWrapper", data: ({ api_call : 'Store', method_call : 'userGetCacheBooks', token : token, Option :{ value: series_id, condition:'all', }, pageCache : 'series', app_platform : 'WEB', page_no : page_no, result_per_page : result_per_page, app_id : app_id }), |
Even though the type of request is POST, but perhaps GET will work too? Let’s try...
1 2 | $ curl "https://www.mebmarket.com/Ajax.php?action=CallWrapper&api_call=Store&method_call=userGetCacheBooks&Option%5Bvalue%5D=563&Option%5Bcondition%5D=all&pageCache=series&page_no=1" {"status":{"success":true,"message":"STOREUsGetCachSuccessGetCache"},"data":{"page_count":2,"count":33,"result_per_page":20,"books":[{"book_id":"49151","series_id":"563","book_publisher":"Siam Inter Comics","category_id":"12","category_name":"\u0e01\u0e32\u0e23\u0e4c\u0e15\u0e39\u0e19","book_name":"EXEcutional \u0e21\u0e2b\u0e32\u0e2a\u0e07\u0e04\u0e23\u0e32\u0e21\u0e2d\u0e2d\u0e19\u0e44\u0e25\u0e19\u0e4c\u0e16\u0e25\u0e48\u0e21\u0e08\u0e31\u0e01\u0e23\u0e27\u0e32\u0e25 \u0e40\u0e25\u0e48\u0e21 32"... |
Exactly what I want! Now, we will turn this to RSS feed by using Huginn.
To scrape this data, create a “Website Agent” with the following configurations:
1 2 3 4 5 6 7 8 9 10 11 | { "expected_update_period_in_days": "2", "url": "https://www.mebmarket.com/Ajax.php?action=CallWrapper&api_call=Store&method_call=userGetCacheBooks&Option%5Bvalue%5D=563&Option%5Bcondition%5D=all&pageCache=series&page_no=1", "type": "json", "mode": "on_change", "extract": { "name": { "path": "$..book_name" } } } |
This uses a query language named JSONPath to scrape all book_name.
Next, we will export this as a feed, so create a “Data Output Agent” with the following configurations:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | { "secrets": [ "THIS_IS_SUPER_SECRET" ], "expected_receive_period_in_days": "2", "template": { "title": "EXEcutional", "description": "EXEcutional", "item": { "title": "{{name}}", "link": "https://www.mebmarket.com/index.php?action=SeriesDetail&series_id=563&page_no=1" } } } |
And set it to read source from the first agent. This completes the setup in Huginn.
Huginn then provides us a URL to access the data. The XML one in particular is in RSS format (it’s actually Atom, but I will call them interchangably), so copy that one and paste it in an RSS reader.